February 08, 2026
Introduction
Current frontier LLMs think to output their best response, maximizing the utility of inference-time compute. However, this process often relies on a passive crutch: the ability to attend to a lossless history. As context length increases, attention mechanisms degrade, and the model’s ability to retrieve relevant info from the distant past falters.
I am investigating this brittleness through a specific lens: active context management.
Distributed-Inventory is an RL environment designed to isolate an LLM’s ability to maintain a coherent state over long horizons without relying on massive context windows. By stripping away the history, the model is forced to transition from a passive reader to an active state manager.
Environment Design
Adhering to the Bitter Lesson, instead of hand-engineering a memory retrieval system, I used RL to force the model to discover its own general-purpose state compression policy.
The environment is built using the verifiers library and trained using prime-rl. A NoiseGenerator deterministically produces an entropic stream of words using a common noun vocabulary. Buried within this stream are commands [GET] and [DROP] which operate on a distinct fantasy item vocabulary.
The critical part is the strict memory wipe. Unlike a standard loop where the model attends to the full history, the conversation context is overriden such that at any turn, the model only sees:
- The system prompt.
- Its own previous output.
- The current chunk of noise and commands.
To survive, the model must explicitly carry the inventory state forward in its own output tokens, effectively treating its generation as a recurrent hidden state. The system prompt establishes this constraint:
"You are an Inventory Manager processing a data stream.\n"
"GOAL: Maintain an accurate list of items based on [GET] and [DROP] commands.\n\n"
"CRITICAL ENVIRONMENTAL CONSTRAINTS:\n"
"1. MEMORY WIPE: After you reply, your entire context window is cleared.\n"
"2. VISIBILITY: The ONLY history you will see in the next turn is the output you write NOW.\n"
"3. ENTROPY: If you do not write a piece of information down, it is deleted from the universe forever.\n\n"
"Survive the stream and report the final inventory when asked."
By using sparse binary rewards, awarded only at the final step, the model is forced to treat intermediate state maintenance not as an auxiliary task, but as a latent variable required to solve the objective.
Results
I trained INTELLECT-3 on a lightweight configuration with a batch size of 16 and 8 rollouts per example. The plots below display the mean reward across the batch.
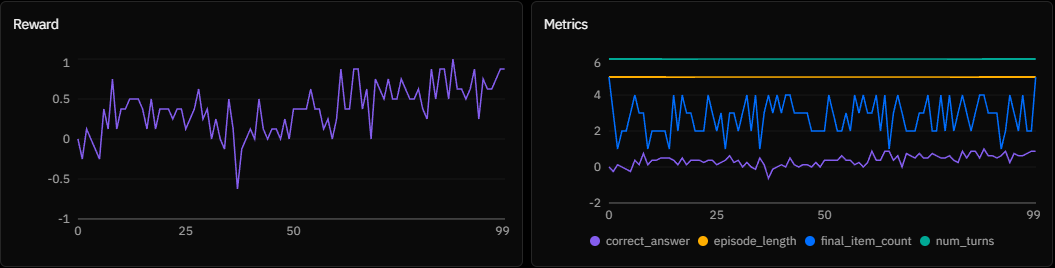 Experiment A:
Experiment A: n_chunks = 5, chunk_size = 100
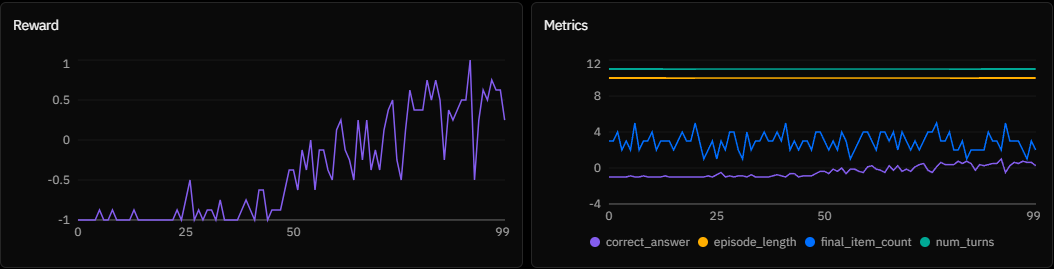 Experiment B:
Experiment B: n_chunks = 10, chunk_size = 1000
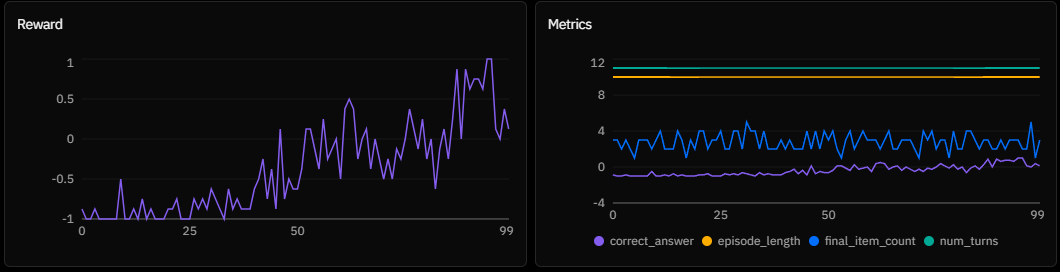 Experiment C:
Experiment C: n_chunks = 10, chunk_size = 1000 (Replication)
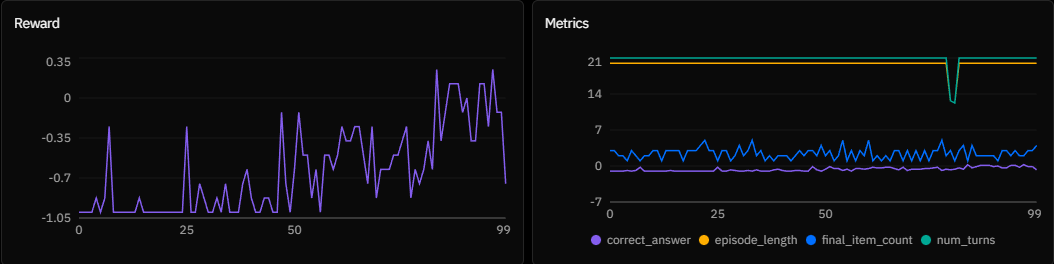 Experiment D:
Experiment D: n_chunks = 20, chunk_size = 1000
Analysis
The constraints reveal that active context management is fundamentally an exploration problem.
1. The Gradient Noise Regime
In Experiment A, the model learns quickly, but the reward curve remains highly oscillatory. This variance is a direct artifact of the small batch size. While the model can maintain state, the gradient updates are noisy, preventing the policy from settling into a stable formatting minimum. This proves the signal is strong enough to recover from bad updates, but optimization is volatile.
2. The Exploration Bottleneck (Grokking)
Experiments B and C display a classic grokking signature: a long period of zero reward followed by a sudden phase transition. This delay is the exploration cost of sparse rewards. With only 8 rollouts per step, the agent wanders blindly for ~40 episodes until it serendipitously generates a valid active state sequence (e.g., prepending Inventory: [Item A]). Once this single successful trajectory is found, the gradients cause the policy to collapse almost instantly onto the solution.
3. The Signal-to-Noise Limit
In Experiment D, the exploration space explodes. The slight incline suggests the model is solving some trajectories, but has hit a sample efficiency wall. The likelihood of randomly generating a correct 20-step maintenance strategy with only 8 attempts per step drops near zero. The signal exists, but without higher rollout diversity or intermediate shaping rewards, the agent cannot bridge the gap between the commands and noise.
Future Work
This experiment validates that INTELLECT-3 can learn Recursive Context Management from scratch via RL. To stabilize long-horizon reasoning, I plan to:
- Scale Up: Increase batch size and rollout count to punch through the exploration bottleneck in longer horizons.
- Curriculum Learning: Initialize with shorter horizons to prime the state-carrying behavior before extending the sequence length.
Distributed-Inventory is available on the Prime Intellect Environments Hub for further exploration. Special thanks to Prime Intellect for the hosted RL beta that made this research possible.